AI Security: July 2024 Press Review

Throughout July, the cybersecurity community highlighted numerous vulnerabilities and attacks targeting Large Language Models (LLMs).
This first issue provides a summary of the top articles I read last month, focusing on the following area:
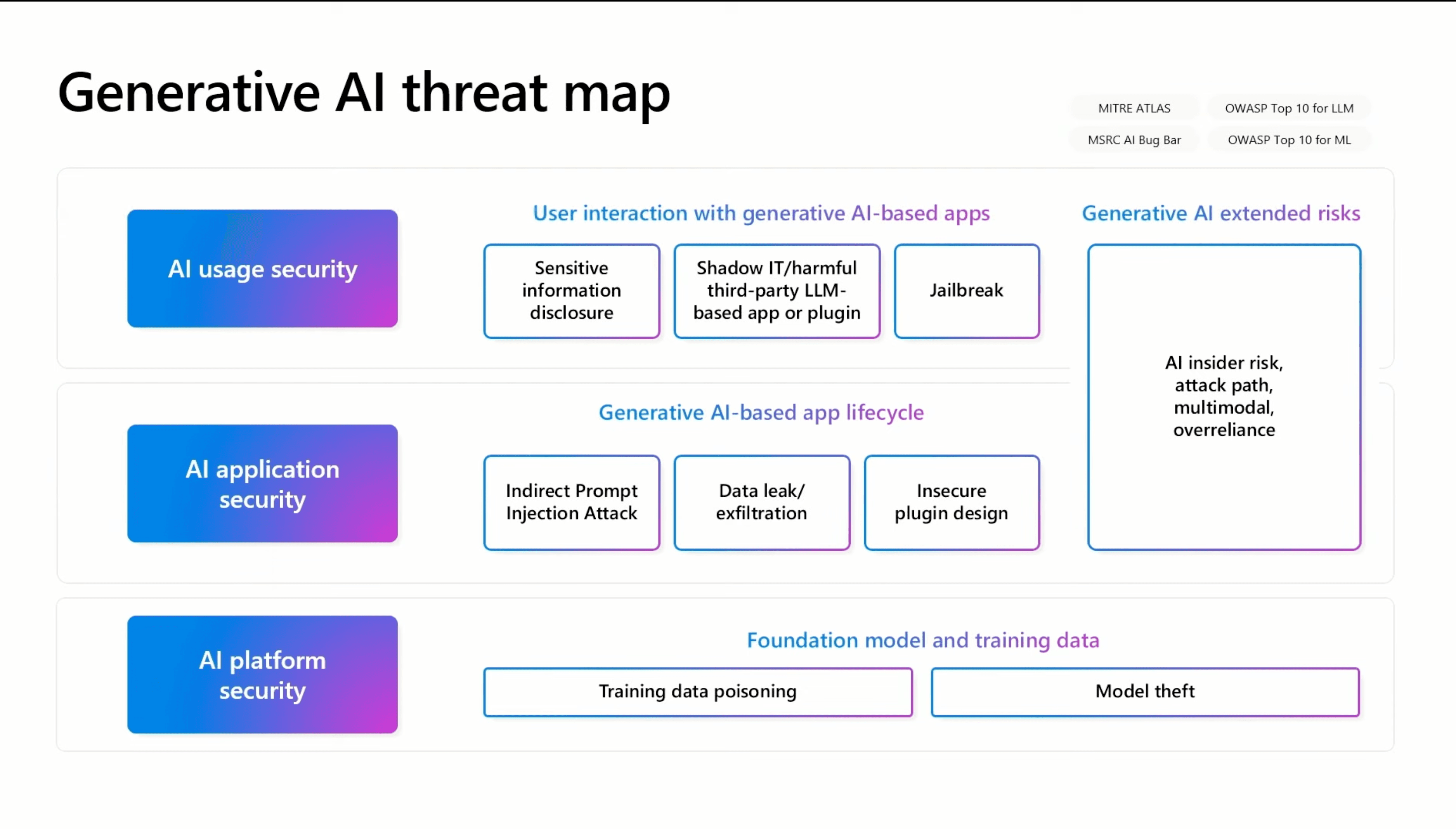
Prompt Injection: Discover how attackers exploit this technique to manipulate LLM responses and carry out a targeted denial-of-service attack.
Audio Attacks: Multimodal LLMs Under Fire. Learn how cybercriminals are using voice commands to "jailbreak" these models.
RAG Application Weaknesses: A case study of "Ask Astro" exposes common flaws in RAG architectures and outlines protective measures.
SSRF and RCE in LangChain: Critical vulnerabilities found in LangChain highlight the importance of keeping AI development libraries and frameworks updated.
Voice Spoofing: Vishing is evolving with AI, enabling attackers to create increasingly realistic voice clones.
The ultimate guide on prompt injection by Jaden Baptista, Algolia
The article presents several techniques and best practices to defend against prompt injection attacks, using prompt injection datasets in particular.
Audio-Based Jailbreak Attacks on Multi-Modal LLMs par Lewis Birch, Mindgard
After text and images, here's how to jailbreak a multimodal LLM using audio.
Auditing the Ask Astro LLM Q&A app par Trail of Bits
The Trail of Bits team conducted a security analysis of the open-source chat application "Ask Astro," which implements A16Z's reference RAG architecture. An analysis full of discoveries and lessons on the security of RAG applications, which are on the rise (and so are security incidents).
How I Discovered a Server-Side Template Injection Vulnerability in LiteLLM par Mevlüt Akçam, Huntr:
The author describes in detail the discovery of a Server-Side Template Injection vulnerability in the LLM proxy LiteLLM.
Whose Voice Is It Anyway? AI-Powered Voice Spoofing for Next-Gen Vishing Attacks Par Emily Astranova, Pascal Issa, Mandiant
This Mandiant article highlights Vishing (voice phishing) attacks using AI-powered voice cloning to impersonate trusted individuals. The Mandiant Red Team conducted a real-world attack simulation, demonstrating the formidable effectiveness of this new threat.
Sorry, ChatGPT Is Under Maintenance: Persistent Denial of Service through Prompt Injection and Memory Attacks, Par Johann Rehberger (wunderwuzzi), Embrace The Red blog
This article highlights a prompt injection attack that affects ChatGPT's memory, causing a persistent denial of service for a target user.
Vulnerabilities in LangChain Gen AI, par Unit42 de Palo Alto
Palo Alto's threat intelligence team, documented two critical vulnerabilities in LangChain discovered in September 2023 (since patched).
The first vulnerability is a Server-Side Request Forgery (SSRF), allowing an attacker to exfiltrate data from internal networks by bypassing access controls.
The second resided in the module for generating code from human language (PALChain), allowing the execution of arbitrary code (Remote Code Execution, RCE) through prompt injection in this module.
These vulnerabilities, although patched, highlight the risks inherent in developing AI applications and the importance of ensuring that the libraries and frameworks used are kept up-to-date.
AI Security Challenge par Wiz
Join this CTF where the goal is to deceive a fictional airline's chatbot to obtain free tickets (hint: check the system prompt by clicking on 'Under The Hood')."